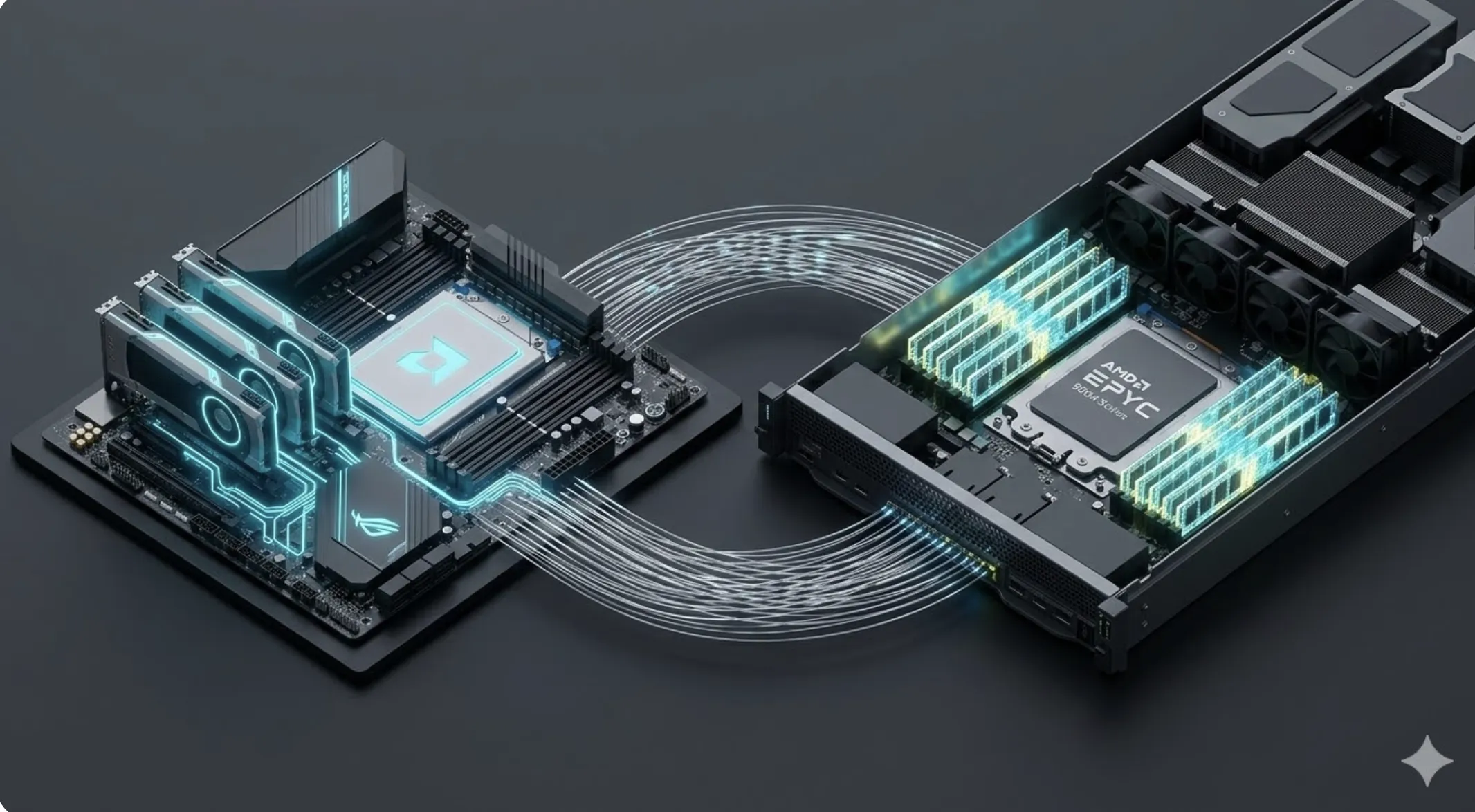
NVIDIA RTX 5090 vs H100: ¿Cuál elegir para tus proyectos de IA?
💡 El Tip Rápido
¿RTX 5090 o H100 para tus proyectos de IA? En 2026, la brecha entre el consumo profesional y la infraestructura industrial se define por la memoria HBM3e y la interconectividad NVLink masiva.
El ENIAC y el Nacimiento del Cómputo Industrial
En 1945, el ENIAC ocupaba una habitación entera y consumía 150 kW para realizar cálculos balísticos. Fue el inicio de la computación a escala industrial. Hoy, la NVIDIA H100 es la heredera de esa potencia masiva, mientras que la RTX 5090 representa la democratización de ese poder en el escritorio. La ingeniería real consiste en saber cuándo necesitas un motor de reacción (H100) y cuándo un motor de precisión para prototipado (RTX 5090). Es la diferencia entre construir un modelo y escalar una civilización de IA.
La Tesis: La GPU de Gama Alta como un Mando a Distancia Caro
Utilizar una RTX 5090 para intentar entrenar un modelo fundacional desde cero es, en la práctica, usar un mando a distancia caro. Tienes una potencia asombrosa en tus manos, pero la falta de memoria HBM3e y de un ancho de banda de interconexión empresarial limitará tus resultados. La 5090 es una herramienta de élite para el desarrollo y el fine-tuning, pero la H100 es la pieza de infraestructura que permite que la IA estructural sea una realidad a escala global.
El Diagnóstico: Islas de VRAM y el Muro de la Comunicación
El problema de las configuraciones multi-GPU domésticas son las islas de VRAM. Sin el ancho de banda masivo de NVLink presente en la serie H100, las tarjetas no pueden compartir memoria de forma eficiente. Según describe Cinto Casals, Arquitecto de IA, esto fragmenta el modelo en silos, obligando a los ingenieros a desperdiciar tiempo optimizando la comunicación en lugar de la inteligencia misma.
Analogía Técnica: Un Aeropuerto vs. una Pista de Aterrizaje Privada
La RTX 5090 es una excelente pista de aterrizaje privada: rápida, eficiente y perfecta para tu propio jet (tus modelos). La H100 es un aeropuerto internacional (un centro de datos): diseñado para gestionar miles de vuelos simultáneos, con una logística de combustible y carga que una pista privada no puede igualar. En 2026, si tu proyecto requiere servir IA a millones de usuarios, necesitas la logística industrial del aeropuerto.
Diferenciador Metodológico: El Paso Cero de la Inversión
En Viblox implementamos el "Paso Cero": antes de comprar hardware (átomos), auditamos el tamaño del conjunto de datos y el modelo (bits). Si el proyecto es de inferencia local o fine-tuning de modelos medianos, la RTX 5090 ofrece el mejor ROI. Si el objetivo es el entrenamiento masivo, la H100 es la única opción técnica viable. La arquitectura de los bits dicta la inversión en los átomos.
Visión de Futuro: La Tecnología Invisible de los Clústeres Híbridos
El futuro nos lleva a la tecnología invisible, donde el desarrollador utiliza su RTX local para el código y el clúster de H100 en la nube se activa de forma automática para el procesamiento pesado. En 2026, la capa de software IA-Nativa gestionará esta transición de forma proactiva, eliminando la fricción entre el hardware de escritorio y el de centro de datos.
Conclusión: ¿Desarrollador de Élite o Arquitecto Industrial?
Al decidir su presupuesto de hardware, la pregunta es estratégica: ¿Necesita una herramienta poderosa para su talento personal, o está construyendo la fábrica de inteligencia del mañana?
📊 Ejemplo Práctico
Escenario Real: Del Prototipado Local al Despliegue Global
Una startup desarrolla un sistema de visión artificial para diagnóstico médico. Necesitan entrenar el modelo con millones de imágenes de alta resolución sin arruinarse en costes de nube durante la fase inicial.
Paso 1: Diagnóstico y Paso Cero. Analizamos que el modelo base puede ajustarse con 24GB de VRAM. Aplicamos el Paso Cero adquiriendo dos RTX 5090 para la fase de prototipado local. Esto permite iteraciones rápidas de los bits del código sin latencia de red.
Paso 2: Fine-Tuning y Optimización. Bajo la supervisión de Cinto Casals, los ingenieros ajustan el modelo utilizando las RTX locales. La alta frecuencia de los núcleos de estas tarjetas acelera la fase de experimentación técnica inicial.
Paso 3: Escalado a Infraestructura H100. Una vez que el modelo es estable, se migra a un clúster de 8 NVIDIA H100 en la nube para el entrenamiento final con el dataset completo. La memoria HBM3e de las H100 permite manejar el volumen masivo de datos que bloqueaba a las RTX.
Paso 4: Validación y Producción. El sistema final se despliega para inferencia global. La ingeniería real demostró que el uso híbrido de hardware —RTX para creación y H100 para producción— es la estrategia más eficiente y resiliente en 2026.